
C#
Better C# Switch Statements for a Range of Values
By hackajob Staff
Ever wondered how to code a binary search tree? It's easier than you think. In previous posts we've looked at How to Implement Linked Lists and also Stacks and Queues in Java, so we thought why not take a deep dive into this infamous data structure that keeps everybody on their toes.
Binary search trees may seem complex but once you've got these concepts nailed down correctly, you’ll fall in love with them. The best bit is, it's much easier than it seems and we'll show you how step-by-step. Keep reading to find out how you can insert nodes in a binary search tree, perform traversals, and also how to delete nodes. You'll be an expert in no time!
Binary search trees (BST) are tree data structures that follow a particular order in the way data is stored. The left subtree of the BST will only contain values that are lesser than the root and the right subtree will only contain values that are greater than the root. Each of the left and right subtrees will themselves be binary search trees following the exact same property.
Binary search trees and binary trees in general have a lot of applications. They are used within a lot of search algorithms where data is constantly going in and out of the system. Binary trees are also used within routing tables in routers. To top it all off, they're an extremely important topic in technical interviews, so the more you know the more prepared you can be!
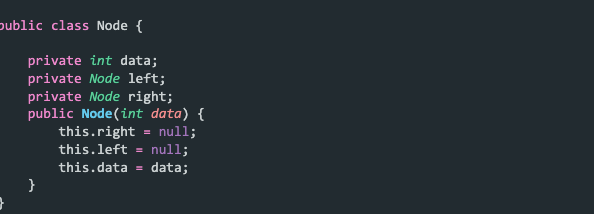
Above is the node class that represents each node of the tree. It has a data field and two fields representing the right and left links of the node. When creating a node, it will be initialised with null for both the left and right links.
Inserting a node into a binary tree has two functions. There's the insertNode method that takes in the data to be inserted. This method calls the insertHelper method, passing through the root node along with the data to be inserted.
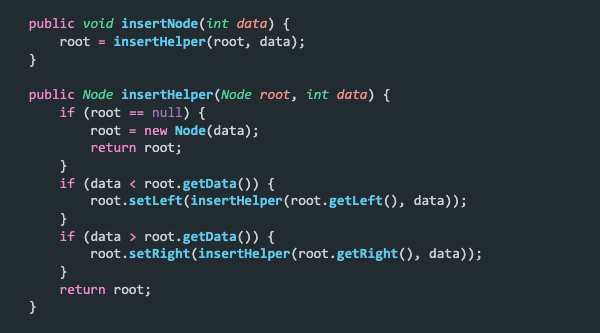
The insertHelper method performs the actual insertion. It's a recursive function and proceeds a little like this: if the root is equal to null, it means that the tree is empty. So, it creates a new node and inserts the data into it, while returning the root node back to the insertNode function. This is used to update the root of the tree.
The next scenario is that the tree isn't empty and the data to be inserted is less than the data present in the root. In this case, we'll insert the node at a location in the left subtree. We recursively call the insertHelper method passing in the left child of the current node and the data to be inserted. Once the base condition is encountered, that is, the root is null, the node will be inserted.
The final scenario is when the tree isn't empty and the data to be inserted is greater than the data present in the root. This node will go to a location that's on the right subtree. We use the same recursive call as we did before, but this time, we proceed down the right subtree and set the right node instead of the left. Great! You've managed to insert a node, now let's find out how to traverse.
Traversing a tree is a very important operation because – similar to linked lists – we have a single entry point to a tree. We need to perform all operations on specific nodes by traversing down from the root node. The types of traversals are characterised by the order in which the nodes are visited. There's three types of traversals: inorder, preorder, and postorder. We'll be looking at each of these using the reference tree below. Further down, we'll also find out why inorder traversal is important when it comes to deleting a node. But let's not get ahead of ourselves, let's start with the basics.
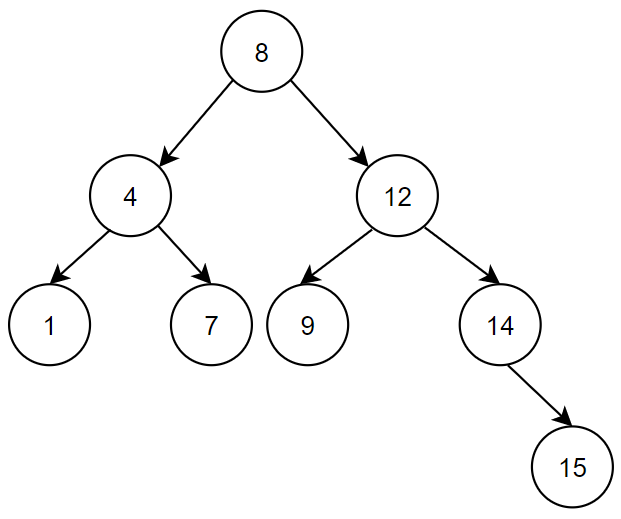
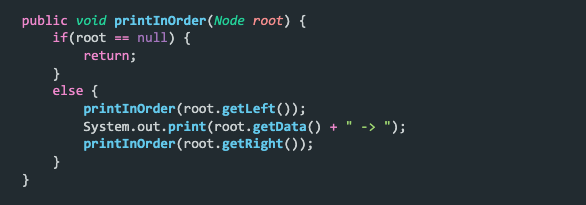
Inorder – In inorder traversal, we follow the LNR order. This means we print the left subtree, followed by the data followed by the right subtree. In the function above, we can see that it is very straightforward with just three lines of code. For the above tree, the inorder traversal will output, 1 -> 4 -> 7 -> 8 -> 9 -> 12 -> 14 -> 15
Preorder – For preorder traversal, we follow the NLR order. We print the node’s data first, then the left subtree, and then the right subtree. For the above tree, the preorder traversal will be, 8 -> 4 -> 1 -> 7 -> 12 -> 9 -> 14 -> 15
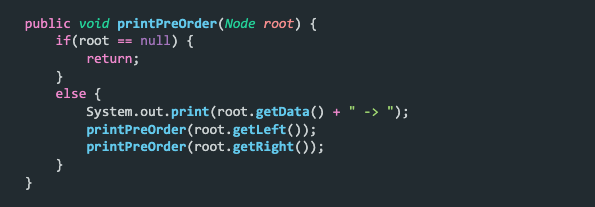
Postorder – Lastly, we have postorder traversal, in which we follow the LRN order. This means we print the left subtree first, followed by the right subtree and then the node’s data. For the tree above, the output will be 1 -> 7 -> 4 -> 9 -> 15 -> 14 -> 12 -> 8.
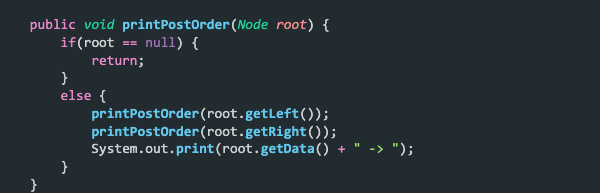
Deletion is usually the most complicated operation in a binary search tree. This is mainly because there are three conditions we need to check before deleting a node. But as you now know how to insert and traverse, this will be a piece of cake.
Leaf nodes, meaning those that don’t have any child nodes can be directly deleted without any issues. Nodes that have a single child are also pretty straightforward. We copy the child node’s value to the node and then delete the child.
Nodes with two children, however, need an additional operation. We need to find the inorder successor of the node having two children and use the value of the successor on the node to be deleted. Once this is done, we delete the inorder successor.
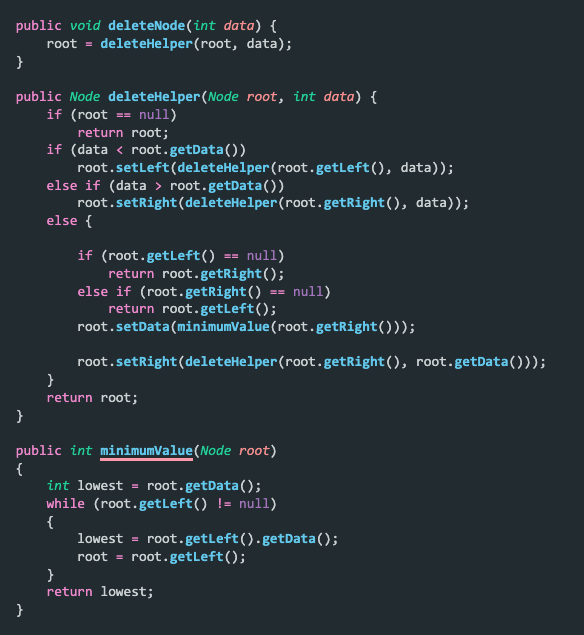
The deleteNode() function and the deleteHelper() function are used for performing the deletion operation. But we also have a helper function called minimumValue() to find the inorder successor of the node to be deleted. deleteNode() accepts the node to be deleted and we traverse the tree to find it. We traverse the tree based on the value of the node, that is, if it is greater than the root node’s data, we move down the right subtree, otherwise the left subtree. This is done recursively until we find the node.
The next step is to check whether it is a leaf-node, a node with one child, or a node with two children. If it's a leaf-node, simply remove that node from the tree. If it's a node that has one child, we copy the child’s data to the node and remove the child. The last scenario is when the node has two children. A node with two children has to be replaced by its inorder successor. The inorder successor is the least value on the right subtree. We find this by continuously traversing down the left node of the right subtree until we reach the end node. This node’s data is copied to the node to be deleted and then it is removed from the tree.
Et voila! Now you know how to implement binary search trees in Java. We hope that you found this article useful but at the same time had fun coding these core concepts. We are sure that these tutorials will come in handy for your next technical interview or your next big project. Happy coding!
Like what you've read or want more like this? Let us know! Email us here or DM us: Twitter, LinkedIn, Facebook, we'd love to hear from you.

