
C#
Better C# Switch Statements for a Range of Values
By hackajob Staff
It's no surprise that Python is one of the most popular open-source programming languages across the globe. You'll find it used in places such as AI, embedded applications, data science, machine learning and – of course – web development. Wondering how you can use Pandas from Python to improve your engineering skills? Wonder no more, we'll get into all of this in our latest tech tutorial. Keep reading to find out.
Pandas, built on top of the Python programming language, is one of the most successful libraries, becoming open-source as of 2009. So what is it? This system provides robust analysis features and data manipulation used within machine learning and data science. And the best bit? It's free, as long as you have a BSD license.

This flexible and fast tool has been created on top of two Python libraries; NumPy and Matplotlib. Such a powerful combination means there's less need for coding, data visualisation and mathematical operations. Through this, data tools are provided to perform a range of tasks such as cleaning, raw data intake and transformation to machine learning and performing data analysis during the lifecycle of data science, which results in high-performing data. Continue reading to explore the basics of Pandas library functions and get started with datasets for machine learning.
DataFrames and Series are two data storage objects that Python offers. So what do these actually mean and what can you do with them?
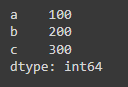
Series are singular, organised data structures with indexes against each column containing homogeneous data. Each series has a set size and this can't be altered, however, the values are able to be altered. Below is a code snippet for a series that has used dictionaries, with the dictionary keys being used to set up an index. Check it out!
Output:
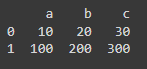
Next is DataFrames. Unlike series, DataFrames are two-dimensional data structures, similar to tables with multiple columns and rows. They're used to store heterogeneous data. When several series are combined, this is when DataFrames are created. With this specific structure, values and size can both change. Take a look at the code snippet below to highlight DataFrame utilising a list of dictionaries.
Output:
To install Pandas you should first download the suitable Anaconda for your operating system, along with the latest Python version, next run the installer, and then follow the stated steps.
To import the Pandas library, use the following command:
One of the most important features of Pandas is the way that it reads all data files whether that be HTML, JSON, Excel, plain text or XML etc. All of the data stored as a CSV file can be used by simply using the read_csv() function.
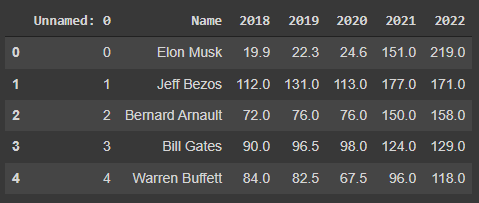
Kaggle is a website to highlight published data and code, on one landing page it shows the top ten billionaires. To view a sample DataFrame stored as a .csv extension on this topic, the following can be replicated.
To write your DataFrame as a .csv file, follow the below.
Pandas library has many functions for manipulating, analysing, cleaning and exploring data. Pandas offers a timesaving solution when working with datasets. Let's take a look at Python pandas library functions for machine learning for beginners.
Before even starting to work with any Pandas dataset, you should first understand the visuals. head() is a simple Pandas function for machine learning, giving the first (n) rows for either a series or DataFrame. Make sure you specify the number of rows as (n), so that no mistakes are made.
Here we use the same billionaire example:
Output:
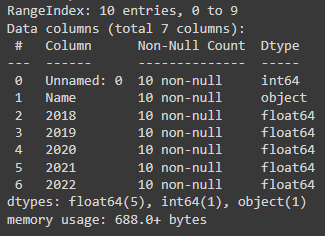
This function is used within dataset exploration to provide a clear summary of the whole data. This concise data overview includes the total number of columns, each column name, range index, memory usage and data type, along with the number of cells in each column with non-null values.
Output:
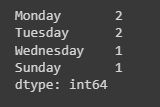
The value_counts() function is used to count the unique values within each dataset. It then gives a series with a unique value count in a downward order, removing missing values on its own.
Output:
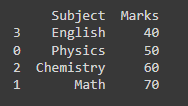
The sort_values() function is used to sort the DataFrame in a rising or decreasing order depending on the chosen column.
Output:
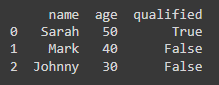
When dealing with large datasets, duplication is often a concern. However, by simply using the drop_duplicates() function, the duplicate rows will be removed from a specific dataset.
Output:
Using the subdivision variables of the drop_duplicates() function to highlight non-consideration columns of the duplicate removal.
Pandas is a powerful, flexible and efficient Python machine learning library. It has a fantastic range of features that deliver many benefits to the user, such as effective large data handling, streamlined representation of data and data personalisation. In addition to this, it can also combine with other libraries to increase performance and productivity. If you are an aspiring data scientist or developer, learning Python Pandas library functions will be extremely advantageous and you will reap the benefits within your industry.
Interested in reading more like this? Let us know! Get in touch with us on Email, Twitter, LinkedIn, Facebook, we'd love to hear from you!

